
t3l1.md 86 KB
| Предыдущая лекция | Следующая лекция | |
|---|---|---|
| Системы контроля версий. | Содержание | [Операторы и операции языка. (./articles/t3l1_2.md) |
Основы языка C
- Пространство имен (Namespace)
- Комментарии
- Документация XML
- Переменные
- Типы данных
- Преобразования типов
- Оператор присваивания
- Операции с числами
Пространство имен
Namespace буквально переводится как "пространство имён". Пространство имен предназначено для обеспечения возможности сохранения одного набора имен отдельно от другого. Названия классов, объявленные в одном пространстве имен, не конфликтуют с теми же именами классов, которые были объявлены в другом.
Определение пространства имен начинается с ключевого слова namespace, за которым следует имя пространства имён:
namespace namespace_name { // ваш код }
Чтобы вызвать класс или функцию, используя пространство имен, добавьте их namespace:
System.Console.WriteLine();
Здесь System и Console это пространства имен, а WriteLine функция, объявленная в этом пространстве имён.
Если объекты из какого-то пространства имен используются очень часто, то можно "подключить" это пространство имен с помощью ключевого слова using:
using System.Console;
...
WriteLine();
Комментарии
Комментарии являются немаловажной частью любого языка программирования, т.к. позволяют удобно пояснять различные участки кода. В C# используются традиционные комментарии в стиле С — однострочные (//...) и многострочные (/* . . . */):
// Это однострочный комментарий
/* Это уже
многострочный комментарий */
Все, что находится в однострочном комментарии — от // до конца строки — игнорируется компилятором, как и весь многострочный комментарий, расположенный между /* и */. Очевидно, что в многострочном комментарии не может присутствовать комбинация */, поскольку она будет трактоваться как конец комментария.
Многострочный комментарий можно помещать в одну строку кода:
Console.WriteLine (/* Здесь идет комментарий! */ "Это скомпилируется");
Встроенные комментарии вроде этого нужно применять осторожно, потому что они могут ухудшить читабельность кода. Однако они удобны при отладке, скажем, когда необходимо временно попробовать запустить программу с указанным другим значением:
DoSomethingMethod (Width, /*Height*/ 100);
Символы комментария, включенные в строковый литерал, конечно же, трактуются как обычные символы:
string s = "/* Это просто нормальная строка */";
Документация XML
В дополнение к комментариям в стиле C, проиллюстрированным выше, в C# имеется очень искусное средство, на которое я хочу обратить особое внимание: способность генерировать документацию в формате XML на основе специальных комментариев. Это однострочные комментарии, начинающиеся с трех слешей (///) вместо двух. В таких комментариях можно размещать XML-дескрипторы, содержащие документацию по типам и членам типов, используемым в коде.
XML-дескрипторы, распознаваемые компилятором, перечислены в следующей таблице:
| Дескриптор | Описание |
|---|---|
<c> |
Помечает текст в строке как код |
<code> |
Помечает множество строк как код |
<example> |
Помечает пример кода |
<exception> |
Документирует класс исключения (синтаксис проверяется компилятором) |
<include> |
Включает комментарии из другого файла документации (синтаксис проверяется компилятором) |
<list> |
Вставляет список в документацию |
<param> |
Помечает параметр метода (синтаксис проверяется компилятором) |
<paramref> |
Указывает, что слово является параметром метода (синтаксис проверяется компилятором) |
<permission> |
Документирует доступ к члену (синтаксис проверяется компилятором) |
<remarks> |
Добавляет описание члена |
<returns> |
Документирует возвращаемое методом значение |
<see> |
Представляет перекрестную ссылку на другой параметр (синтаксис проверяется компилятором) |
<seealso> |
Представляет раздел "see also" ("смотреть также") в описании (синтаксис проверяется компилятором) |
<summary> |
Представляет краткий итог о типе или члене |
<value> |
Описывает свойство |
Чтобы увидеть, как это работает, рассмотрим пример кода, в который добавим некоторые XML-комментарии:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace ConsoleApplication1
{
/// <summary>
/// Класс Program
/// основной класс программы
/// выводящий текст "Hello, World!"
/// </summary>
class Program
{
/// <summary>
/// Метод Main() является
/// входной точкой работы программы
/// </summary>
/// <param name="args">Аргумент метода Main()</param>
static void Main(string[] args)
{
// Форматируем шапку программы
Console.BackgroundColor = ConsoleColor.Green;
Console.ForegroundColor = ConsoleColor.Black;
Console.WriteLine("********************");
Console.WriteLine("**** Мой проект ****");
Console.WriteLine("********************");
// Основная программа
Console.BackgroundColor = ConsoleColor.Black;
Console.ForegroundColor = ConsoleColor.Green;
Console.WriteLine();
Console.WriteLine("Hello, World!");
// Ожидание нажатия клавиши Enter перед завершением работы
Console.ReadLine();
}
}
}
Компилятор C# может извлекать XML-элементы из специальных комментариев и использовать их для генерации файлов XML. Чтобы заставить компилятор сгенерировать XML-документацию для сборки, указывается опция /doc вместе с именем файла, который должен быть создан:
csc /t:library /doc:MyApplication.xml MyApplication.cs
Данная команда сгенерирует файл XML с именем MyApplication.xml со следующим содержимым:
<?xml version="1.0"?>
<doc>
<assembly>
<name>Program
</assembly>
<members>
<member name="T:ConsoleApplication1.Program">
<summary>
Класс Program
основной класс программы
выводящий текст "Hello, World!"
</summary>
</member>
<member name="M:ConsoleApplication1.Program.Main(System.String[])">
<summary>
Метод Main() является
входной точкой работы программы
</summary>
<param name="args">Аргумент метода Main()</param>
</member>
</members>
</doc>
Обратите внимание на то, что компилятор на самом деле выполнил некоторую работу за вас: он создал элемент <assembly> и также добавил элементы <member> для каждого члена класса в этом файле. Каждый элемент <member> имеет атрибут name с полным именем члена, снабженным префиксом — буквой, который указывает на то, является он типом (Т:), полем (F:) или членом (М:).
Переменные
Для хранения данных в программе в C#, как и в других языках программирования, применяются переменные. Переменная представляет именованный участок памяти, который хранит некоторое значение.
В C# существуют две разновидности типов: ссылочные типы и типы значений. Переменные типа значений содержат непосредственно данные, а в переменных ссылочных типов хранятся ссылки на нужные данные, которые именуются объектами. Две переменные ссылочного типа могут ссылаться на один и тот же объект, поэтому может случиться так, что операции над одной переменной затронут объект, на который ссылается другая переменная. Каждая переменная типа значения имеет собственную копию данных, и операции над одной переменной не могут затрагивать другую (за исключением переменных параметров ref и out).
Каждая переменная характеризуется определенным именем, типом данных и значением. Имя переменной представляет поизвольный идентификатор, который может содержать алфавитно-цифровые символы или символ подчеркивания и должен начинаться либо с алфавитного символа, либо со знака подчеркивания.
Синтаксис объявления переменных в C# выглядит следующим образом:
ТипДанных Идентификатор
Например, определим переменную age:
int age;
Объявить можно переменную любого действительного типа. Важно подчеркнуть, что возможности переменной определяются ее типом. Например, переменную типа bool нельзя использовать для хранения числовых значений с плавающей точкой. Кроме того, тип переменной нельзя изменять в течение срока ее существования. В частности, переменную типа int нельзя преобразовать в переменную типа char.
Все переменные в C# должны быть объявлены до их применения. Это нужно для того, чтобы уведомить компилятор о типе данных, хранящихся в переменной, прежде чем он попытается правильно скомпилировать любой оператор, в котором используется переменная. Это позволяет также осуществлять строгий контроль типов в C#.
Инициализация переменной
Задать значение переменной можно, в частности, с помощью оператора присваивания. Кроме того, задать начальное значение переменной можно при ее объявлении. Для этого после имени переменной указывается знак равенства (=) и присваиваемое значение. Если две или более переменные одного и того же типа объявляются списком, разделяемым запятыми, то этим переменным можно задать, например, начальное значение. Ниже приведена общая форма инициализации переменной:
// задаем целочисленной переменной i значение 10
int i = 10;
// инициализируем переменную symbol буквенным значением Z
char symbol = 'Z';
// переменная f инициализируется числовым значением 15.7
float f = 15.7F;
// инициализируем несколько переменных одного типа
int x = 5, y = 10, z = 12;
Инициализация переменных демонстрирует пример обеспечения безопасности C#. Коротко говоря, компилятор C# требует, чтобы любая переменная была инициализирована некоторым начальным значением, прежде чем можно было обратиться к ней в какой-то операции. В большинстве современных компиляторов нарушение этого правила определяется и выдается соответствующее предупреждение, но "всевидящий" компилятор C# трактует такие нарушения как ошибки. Это предохраняет от нечаянного получения значений "мусора" из памяти, оставшегося там от других программ.
В C# используются два метода для обеспечения инициализации переменных перед пользованием:
Переменные, являющиеся полями класса или структуры, если не инициализированы явно, по умолчанию обнуляются в момент создания.
Переменные, локальные по отношению к методу, должны быть явно инициализированы в коде до появления любого оператора, в котором используются их значения. В данном случае при объявлении переменной ее инициализация не происходит автоматически, но компилятор проверит все возможные пути потока управления в методе и сообщит об ошибке, если обнаружит любую возможность использования значения этой локальной переменной до ее инициализации.
Динамическая инициализация
В приведенных выше примерах в качестве инициализаторов переменных использовались только константы, но в C# допускается также динамическая инициализация переменных с помощью любого выражения, действительного на момент объявления переменной:
int i1 = 3, i2 = 4;
// Инициализируем динамически переменную result
double result = Math.Sqrt(i1*i1 + i2*i2);
В данном примере объявляются три локальные переменные i1, i2, result, первые две из которых инициализируются константами, а переменная result инициализируется динамически с использованием метода Math.Sqrt(), возвращающего квадратный корень выражения. Следует особо подчеркнуть, что в выражении для инициализации можно использовать любой элемент, действительный на момент самой инициализации переменной, в том числе вызовы методов, другие переменные или литералы.
Неявно типизированные переменные
Как пояснялось выше, все переменные в C# должны быть объявлены. Как правило, при объявлении переменной сначала указывается тип, например int или bool, а затем имя переменной. Но начиная с версии C# 3.0, компилятору предоставляется возможность самому определить тип локальной переменной, исходя из значения, которым она инициализируется. Такая переменная называется неявно типизированной.
Неявно типизированная переменная объявляется с помощью ключевого слова var и должна быть непременно инициализирована. Для определения типа этой переменной компилятору служит тип ее инициализатора, т.е. значения, которым она инициализируется:
// переменная i инициализируется целочисленным литералом
var i = 12;
// переменная d инициализируется литералом с плавающей точкой,имеющему тип double
var d = 12.3;
// переменная f имеет тип float
var f = 0.34F;
Единственное отличие неявно типизированной переменной от обычной, явно типизированной переменной, — в способе определения ее типа. Как только этот тип будет определен, он закрепляется за переменной до конца ее существования.
Неявно типизированные переменные внедрены в C# не для того, чтобы заменить собой обычные объявления переменных. Напротив, неявно типизированные переменные предназначены для особых случаев, и самый примечательный из них имеет отношение к языку интегрированных запросов (LINQ). Таким образом, большинство объявлений переменных должно и впредь оставаться явно типизированными, поскольку они облегчают чтение и понимание исходного текста программы.
Константы
Как следует из названия, константа — это переменная, значение которой не меняется за время ее существования. Предваряя переменную ключевым словом const при ее объявлении и инициализации, вы объявляете ее как константу:
// Это значение не может быть изменено
const int a = 100;
Ниже перечислены основные характеристики констант:
Они должны инициализироваться при объявлении, и однажды присвоенные им значения никогда не могут быть изменены.
Значение константы должно быть вычислено во время компиляции. Таким образом, инициализировать константу значением, взятым из другой переменной, нельзя. Если все-таки нужно это сделать, используйте поля только для чтения.
Константы всегда неявно статические. Однако вы не должны (и фактически не можете) включать модификатор static в объявление константы.
Использование констант в программах обеспечивает, по крайней мере, три преимущества:
Константы облегчают чтение программ, заменяя "магические" числа и строки читаемыми именами, назначение которых легко понять.
Константы облегчают модификацию программ. Например, предположим, что в программе C# имеется константа SalesTax (налог с продаж), которой присвоено значение 6 процентов. Если налог с продаж когда-нибудь изменится, вы можете модифицировать все вычисления налога, просто присвоив новое значение этой константе, и не понадобится просматривать код в поисках значений и изменять каждое из них, надеясь, что оно нигде не будет пропущено.
Константы позволяют избежать ошибок в программах. Если попытаться присвоить новое значение константе где-то в другом месте программы, а не там, где она объявлена, компилятор выдаст сообщение об ошибке.
Типы данных
Типы данных имеют особенное значение в C#, поскольку это строго типизированный язык. Это означает, что все операции подвергаются строгому контролю со стороны компилятора на соответствие типов, причем недопустимые операции не компилируются. Следовательно, строгий контроль типов позволяет исключить ошибки и повысить надежность программ. Для обеспечения контроля типов все переменные, выражения и значения должны принадлежать к определенному типу. Такого понятия, как "бестиповая" переменная, в данном языке программирования вообще не существует. Более того, тип значения определяет те операции, которые разрешается выполнять над ним. Операция, разрешенная для одного типа данных, может оказаться недопустимой для другого.
В C# имеются две общие категории встроенных типов данных: типы значений и ссылочные типы. Они отличаются по содержимому переменной. Концептуально разница между ними состоит в том, что тип значения (value type) хранит данные непосредственно, в то время как ссылочный тип (reference type) хранит ссылку на значение.
Эти типы сохраняются в разных местах памяти: типы значений сохраняются в области, известной как стек, а ссылочные типы — в области, называемой управляемой кучей.
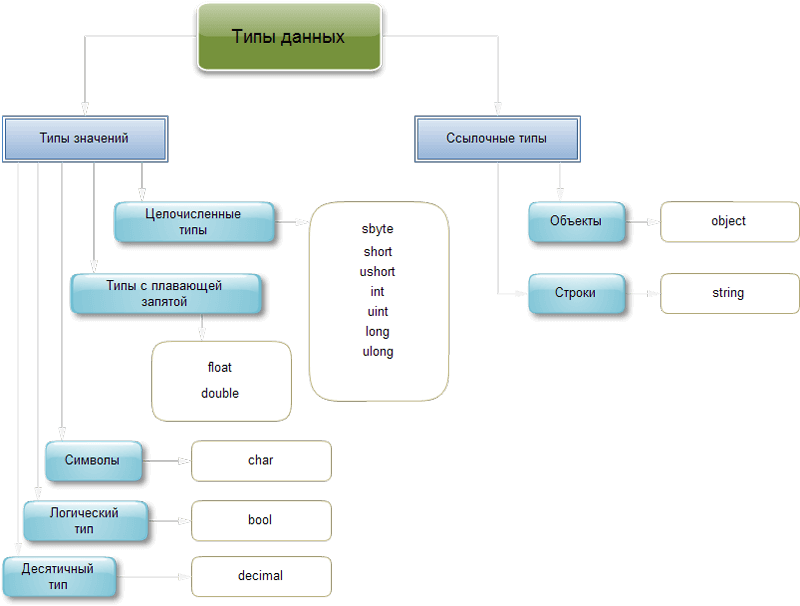
Давайте разберем типы значений.
Целочисленные типы
В C# определены девять целочисленных типов: char, byte, sbyte, short, ushort, int, uint, long и ulong. Но тип char применяется, главным образом, для представления символов и поэтому рассматривается отдельно. Остальные восемь целочисленных типов предназначены для числовых расчетов. Ниже представлены их диапазон представления чисел и разрядность в битах:
| Тип | Тип CTS | Разрядность в битах | Диапазон |
|---|---|---|---|
| byte | System.Byte | 8 | 0..255 |
| sbyte | System.SByte | 8 | -128..127 |
| short | System.Int16 | 16 | -32768..32767 |
| ushort | System.UInt16 | 16 | 0..65535 |
| int | System.Int32 | 32 | -2147483648..2147483647 |
| uint | System.UInt32 | 32 | 0..4294967295 |
| long | System.Int64 | 64 | -9223372036854775808..9223372036854775807 |
| ulong | System.UInt64 | 64 | 0..18446744073709551615 |
Как следует из приведенной выше таблицы, в C# определены оба варианта различных целочисленных типов: со знаком и без знака. Целочисленные типы со знаком отличаются от аналогичных типов без знака способом интерпретации старшего разряда целого числа. Так, если в программе указано целочисленное значение со знаком, то компилятор C# сгенерирует код, в котором старший разряд целого числа используется в качестве флага знака. Число считается положительным, если флаг знака равен 0, и отрицательным, если он равен 1.
Отрицательные числа практически всегда представляются методом дополнения до двух, в соответствии с которым все двоичные разряды отрицательного числа сначала инвертируются, а затем к этому числу добавляется 1.
Вероятно, самым распространенным в программировании целочисленным типом является тип int. Переменные типа int нередко используются для управления циклами, индексирования массивов и математических расчетов общего назначения. Когда же требуется целочисленное значение с большим диапазоном представления чисел, чем у типа int, то для этой цели имеется целый ряд других целочисленных типов.
Так, если значение нужно сохранить без знака, то для него можно выбрать тип uint, для больших значений со знаком — тип long, а для больших значений без знака — тип ulong. В качестве примера ниже приведена программа, вычисляющая расстояние от Земли до Солнца в сантиметрах. Для хранения столь большого значения в ней используется переменная типа long:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
long result;
const long km = 149800000; // расстояние в км.
result = km * 1000 * 100;
Console.WriteLine(result);
Console.ReadLine();
}
}
}
Всем целочисленным переменным значения могут присваиваться в десятичной или шестнадцатеричной системе обозначений. В последнем случае требуется префикс 0x:
long x = 0x12ab;
Если возникает какая-то неопределенность относительно того, имеет ли целое значение тип int, uint, long или ulong, то по умолчанию принимается int. Чтобы явно специфицировать, какой другой целочисленный тип должно иметь значение, к числу можно добавлять следующие символы:
uint ui = 1234U;
long l = 1234L;
ulong ul = 1234UL;
U и L можно также указывать в нижнем регистре, хотя строчную L легко зрительно спутать с цифрой 1 (единица).
Типы с плавающей точкой
Типы с плавающей точкой позволяют представлять числа с дробной частью. В C# имеются две разновидности типов данных с плавающей точкой: float и double. Они представляют числовые значения с одинарной и двойной точностью соответственно. Так, разрядность типа float составляет 32 бита, что приближенно соответствует диапазону представления чисел от 5E-45 до 3,4E+38. А разрядность типа double составляет 64 бита, что приближенно соответствует диапазону представления чисел от 5E-324 до 1,7Е+308.
Тип данных float предназначен для меньших значений с плавающей точкой, для которых требуется меньшая точность. Тип данных double больше, чем float, и предлагает более высокую степень точности (15 разрядов).
Если нецелочисленное значение жестко кодируется в исходном тексте (например, 12.3), то обычно компилятор предполагает, что подразумевается значение типа double. Если значение необходимо специфицировать как float, потребуется добавить к нему символ F (или f):
float f = 12.3F;
Десятичный тип данных
Для представления чисел с плавающей точкой высокой точности предусмотрен также десятичный тип decimal, который предназначен для применения в финансовых расчетах. Этот тип имеет разрядность 128 бит для представления числовых значений в пределах от 1Е-28 до 7,9Е+28. Вам, вероятно, известно, что для обычных арифметических вычислений с плавающей точкой характерны ошибки округления десятичных значений. Эти ошибки исключаются при использовании типа decimal, который позволяет представить числа с точностью до 28 (а иногда и 29) десятичных разрядов. Благодаря тому что этот тип данных способен представлять десятичные значения без ошибок округления, он особенно удобен для расчетов, связанных с финансами:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
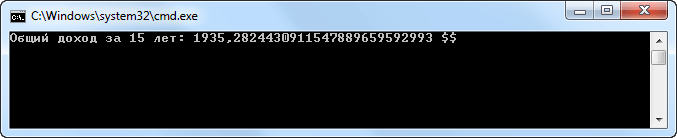
// *** Расчет стоимости капиталовложения с ***
// *** фиксированной нормой прибыли***
decimal money, percent;
int i;
const byte years = 15;
money = 1000.0m;
percent = 0.045m;
for (i = 1; i <= years; i++)
{
money *= 1 + percent;
}
Console.WriteLine("Общий доход за {0} лет: {1} $$",years,money);
Console.ReadLine();
}
}
}
Результатом работы данной программы будет:
Символы
В C# символы представлены не 8-разрядным кодом, как во многих других языках программирования, например С++, а 16-разрядным кодом, который называется юникодом (Unicode). В юникоде набор символов представлен настолько широко, что он охватывает символы практически из всех естественных языков на свете. Если для многих естественных языков, в том числе английского, французского и немецкого, характерны относительно небольшие алфавиты, то в ряде других языков, например китайском, употребляются довольно обширные наборы символов, которые нельзя представить 8-разрядным кодом. Для преодоления этого ограничения в C# определен тип char, представляющий 16-разрядные значения без знака в пределах от 0 до 65 535. При этом стандартный набор символов в 8-разрядном коде ASCII является подмножеством юникода в пределах от 0 до 127. Следовательно, символы в коде ASCII по-прежнему остаются действительными в C#.
Для того чтобы присвоить значение символьной переменной, достаточно заключить это значение (т.е. символ) в одинарные кавычки:
char ch;
ch = 'Z';
Несмотря на то что тип char определен в C# как целочисленный, его не следует путать со всеми остальными целочисленными типами. Дело в том, что в C# отсутствует автоматическое преобразование символьных значений в целочисленные и обратно. Например, следующий фрагмент кода содержит ошибку:
char ch;
ch = 8; // ошибка, не выйдет
Наравне с представлением char как символьных литералов, их можно представлять как 4-разрядные шестнадцатеричные значения Unicode (например, \u0041), целочисленные значения с приведением (например, (char) 65) или же шестнадцатеричные значения (например, \x0041). Кроме того, они могут быть представлены в виде управляющих последовательностей.
Логический тип данных
Тип bool представляет два логических значения: "истина" и "ложь". Эти логические значения обозначаются в C# зарезервированными словами true и false соответственно. Следовательно, переменная или выражение типа bool будет принимать одно из этих логических значений. Кроме того, в C# не определено взаимное преобразование логических и целых значений. Например, 1 не преобразуется в значение true, а 0 — в значение false.
Литералы
В C# литералами называются постоянные значения, представленные в удобной для восприятия форме. Например, число 100 является литералом. Сами литералы и их назначение настолько понятны, что они применялись во всех предыдущих примерах программ без всяких пояснений. Но теперь настало время дать им формальное объяснение.
В C# литералы могут быть любого простого типа. Представление каждого литерала зависит от конкретного типа. Как пояснялось ранее, символьные литералы заключаются в одинарные кавычки. Например, 'а' и '%' являются символьными литералами.
Целочисленные литералы указываются в виде чисел без дробной части. Например, 10 и -100 — это целочисленные литералы. Для обозначения литералов с плавающей точкой требуется указывать десятичную точку и дробную часть числа. Например, 11.123 — это литерал с плавающей точкой. Для вещественных чисел с плавающей точкой в C# допускается также использовать экспоненциальное представление.
У литералов должен быть также конкретный тип, поскольку C# является строго типизированным языком. В этой связи возникает естественный вопрос: к какому типу следует отнести числовой литерал, например 2, 12 3987 или 0.23? К счастью, для ответа на этот вопрос в C# установлен ряд простых для соблюдения правил:
У целочисленных литералов должен быть самый мелкий целочисленный тип, которым они могут быть представлены, начиная с типа int. Таким образом, у целочисленных литералов может быть один из следующих типов: int, uint, long или ulong в зависимости от значения литерала.
Литералы с плавающей точкой относятся к типу double.
Если вас не устраивает используемый по умолчанию тип литерала, вы можете явно указать другой его тип с помощью суффикса.
Так, для указания типа long к литералу присоединяется суффикс l или L. Например, 12 — это литерал типа int, a 12L — литерал типа long. Для указания целочисленного типа без знака к литералу присоединяется суффикс u или U. Следовательно, 100 — это литерал типа int, a 100U — литерал типа uint. А для указания длинного целочисленного типа без знака к литералу присоединяется суффикс ul или UL. Например, 984375UL — это литерал типа ulong.
Кроме того, для указания типа float к литералу присоединяется суффикс F или f. Например, 10.19F — это литерал типа float. Можете даже указать тип double, присоединив к литералу суффикс d или D, хотя это излишне. Ведь, как упоминалось выше, по умолчанию литералы с плавающей точкой относятся к типу double.
И наконец, для указания типа decimal к литералу присоединяется суффикс m или М. Например, 9.95М — это десятичный литерал типа decimal.
Несмотря на то что целочисленные литералы образуют по умолчанию значения типа int, uint, long или ulong, их можно присваивать переменным типа byte, sbyte, short или ushort, при условии, что присваиваемое значение может быть представлено целевым типом.
Шестнадцатеричные литералы
Вам, вероятно, известно, что в программировании иногда оказывается проще пользоваться системой счисления по основанию 16, чем по основанию 10. Система счисления по основанию 16 называется шестнадцатеричной. В ней используются числа от 0 до 9, а также буквы от А до F, которыми обозначаются десятичные числа 10,11,12,13, 14 и 15. Например, десятичному числу 16 соответствует шестнадцатеричное число 10. Вследствие того что шестнадцатеричные числа применяются в программировании довольно часто, в C# разрешается указывать целочисленные литералы в шестнадцатеричном формате. Шестнадцатеричные литералы должны начинаться с символов 0x, т.е. нуля и последующей латинской буквы "икс". Ниже приведены некоторые примеры шестнадцатеричных литералов:
count = 0xFF; // равно 255 в десятичной системе
incr = 0x1a; // равно 26 в десятичной системе
Управляющие последовательности символов
Большинство печатаемых символов достаточно заключить в одинарные кавычки, но набор в текстовом редакторе некоторых символов, например возврата каретки, вызывает особые трудности. Кроме того, ряд других символов, в том числе одинарные и двойные кавычки, имеют специальное назначение в C#, поэтому их нельзя использовать непосредственно. По этим причинам в C# предусмотрены специальные управляющие последовательности символов:
| Управляющая последовательность | Описание |
|---|---|
| \a | Звуковой сигнал (звонок) |
| \b | Возврат на одну позицию |
| \f | Перевод страницы (переход на новую страницу) |
| \n | Новая строка (перевод строки) |
| \r | Возврат каретки |
| \t | Горизонтальная табуляция |
| \v | Вертикальная табуляция |
| \0 | Пустой символ |
\' |
Одинарная кавычка |
\" |
Двойная кавычка |
\\ |
Обратная косая черта |
Строковые литералы
В C# поддерживается еще один тип литералов — строковый. Строковый литерал представляет собой набор символов, заключенных в двойные кавычки. Например следующий фрагмент кода:
"This is text"
Помимо обычных символов, строковый литерал может содержать одну или несколько управляющих последовательностей символов, о которых речь шла выше. Также можно указать буквальный строковый литерал. Такой литерал начинается с символа @, после которого следует строка в кавычках. Содержимое строки в кавычках воспринимается без изменений и может быть расширено до двух и более строк. Это означает, что в буквальный строковый литерал можно включить символы новой строки, табуляции и прочие, не прибегая к управляющим последовательностям. Единственное исключение составляют двойные кавычки ("), для указания которых необходимо использовать двойные кавычки с обратным слэшем ("\"). Например:
// Используем перенос строки
Console.WriteLine("Первая строка\nВторая строка\nТретья строка\n");
// Используем вертикальную табуляцию
Console.WriteLine("Первый столбец \v Второй столбец \v Третий столбец \n");
// Используем горизонтальную табуляцию
Console.WriteLine("One\tTwo\tThree");
Console.WriteLine("Four\tFive\tSix\n");
//Вставляем кавычки
Console.WriteLine("\"Зачем?\", - спросил он");
Нижние подчеркивания в числовых литералах
Вы можете использовать нижние подчеркивания, чтобы сделать числовые константы более читаемыми:
var oneMillion = 1_000_000;
var creditCardNumber = 1234_5678_9012_3456L;
var socialSecurityNumber = 999_99_9999L;
var hexBytes = 0xFF_EC_DE_5E;
var bytes = 0b11010010_01101001_10010100_10010010;
Преобразования типов
В программировании нередко значения переменных одного типа присваиваются переменным другого типа. Например, в приведенном ниже фрагменте кода целое значение типа int присваивается переменной с плавающей точкой типа float:
int i;
float f;
i = 10;
f = i; // присвоить целое значение переменной типа float
Если в одной операции присваивания смешиваются совместимые типы данных, то значение в правой части оператора присваивания автоматически преобразуется в тип, указанный в левой его части. Поэтому в приведенном выше фрагменте кода значение переменной i сначала преобразуется в тип float, а затем присваивается переменной f. Но вследствие строгого контроля типов далеко не все типы данных в C# оказываются полностью совместимыми, а следовательно, не все преобразования типов разрешены в неявном виде. Например, типы bool и int несовместимы. Правда, преобразование несовместимых типов все-таки может быть осуществлено путем приведения. Приведение типов, по существу, означает явное их преобразование.
Автоматическое преобразование типов
Когда данные одного типа присваиваются переменной другого типа, неявное преобразование типов происходит автоматически при следующих условиях:
- оба типа совместимы
- диапазон представления чисел целевого типа шире, чем у исходного типа
Если оба эти условия удовлетворяются, то происходит расширяющее преобразование. Например, тип int достаточно крупный, чтобы вмещать в себя все действительные значения типа byte, а кроме того, оба типа, int и byte, являются совместимыми целочисленными типами, и поэтому для них вполне возможно неявное преобразование.
Числовые типы, как целочисленные, так и с плавающей точкой, вполне совместимы друг с другом для выполнения расширяющих преобразований. Рассмотрим пример:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
short num1, num2;
num1 = 10;
num2 = 15;
Console.WriteLine("{0} + {1} = {2}",num1,num2,Sum(num1,num2));
Console.ReadLine();
}
static int Sum(int x, int y)
{
return x + y;
}
}
}
Обратите внимание на то, что метод Sum() ожидает поступления двух параметров типа int. Тем не менее, в методе Main() ему на самом деле передаются две переменных типа short. Хотя это может показаться несоответствием типов, программа будет компилироваться и выполняться без ошибок и возвращать в результате, как и ожидалось, значение 25.
Причина, по которой компилятор будет считать данный код синтаксически корректным, связана с тем, что потеря данных здесь невозможна. Поскольку максимальное значение (32767), которое может содержать тип short, вполне вписывается в рамки диапазона типа int (максимальное значение которого составляет 2147483647), компилятор будет неявным образом расширять каждую переменную типа short до типа int. Формально термин "расширение" применяется для обозначения неявного восходящего приведения (upward cast), которое не приводит к потере данных.
Приведение несовместимых типов
Несмотря на всю полезность неявных преобразований типов, они неспособны удовлетворить все потребности в программировании, поскольку допускают лишь расширяющие преобразования совместимых типов. А во всех остальных случаях приходится обращаться к приведению типов. Приведение — это команда компилятору преобразовать результат вычисления выражения в указанный тип. А для этого требуется явное преобразование типов. Ниже приведена общая форма приведения типов:
(целевой_тип) выражение
Здесь целевой_тип обозначает тот тип, в который желательно преобразовать указанное выражение.
Если приведение типов приводит к сужающему преобразованию, то часть информации может быть потеряна. Например, в результате приведения типа long к типу int часть информации потеряется, если значение типа long окажется больше диапазона представления чисел для типа int, поскольку старшие разряды этого числового значения отбрасываются. Когда же значение с плавающей точкой приводится к целочисленному, то в результате усечения теряется дробная часть этого числового значения. Так, если присвоить значение 1,23 целочисленной переменной, то в результате в ней останется лишь целая часть исходного числа (1), а дробная его часть (0,23) будет потеряна. Давайте рассмотрим пример:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
int i1 = 455, i2 = 84500;
decimal dec = 7.98845m;
// Приводим два числа типа int
// к типу short
Console.WriteLine((short)i1);
Console.WriteLine((short)i2);
// Приводим число типа decimal
// к типу int
Console.WriteLine((int)dec);
Console.ReadLine();
}
}
}
Результатом работы данной программы будет:

Обратите внимание, что переменная i1 корректно преобразовалась в тип short, т.к. ее значение входит в диапазон этого типа данных. Преобразование переменной dec в тип int вернуло целую часть этого числа. Преобразование переменной i2 вернуло значение переполнения 18964 (т.е. 84500 - 2*32768).
Перехват сужающих преобразований данных
В предыдущем примере приведение переменной i2 к типу short не является приемлемым, т.к. возникает потеря данных. Для создания приложений, в которых потеря данных должна быть недопустимой, в C# предлагаются такие ключевые слова, как checked и unchecked, которые позволяют гарантировать, что потеря данных не окажется незамеченной.
По умолчанию, в случае, когда не предпринимается никаких соответствующих исправительных мер, условия переполнения (overflow) и потери значимости (underflow) происходят без выдачи ошибки. Обрабатывать условия переполнения и потери значимости в приложении можно двумя способами. Это можно делать вручную, полагаясь на свои знания и навыки в области программирования.
Недостаток такого подхода в том, что даже в случае приложения максимальных усилий человек все равно остается человеком, и какие-то ошибки могут ускользнуть от его глаз.
К счастью, в C# предусмотрено ключевое слово checked. Если оператор (или блок операторов) заключен в контекст checked, компилятор C# генерирует дополнительные CIL-инструкции, обеспечивающие проверку на предмет условий переполнения, которые могут возникать в результате сложения, умножения, вычитания или деления двух числовых типов данных.
В случае возникновения условия переполнения во время выполнения будет генерироваться исключение System.OverflowException. Давайте рассмотрим пример, в котором будем передавать в консоль значение исключения:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
byte var1 = 250;
byte var2 = 150;
try
{
byte sum = checked((byte)(var1+var2));
Console.WriteLine("Сумма: {0}", sum);
}
catch (OverflowException ex)
{
Console.WriteLine(ex.Message);
Console.ReadLine();
}
}
}
}
Результат работы данной программы:
Переполнение в результате выполнения арифметической операции.
Настройка проверки на предмет возникновения условий переполнения в масштабах проекта
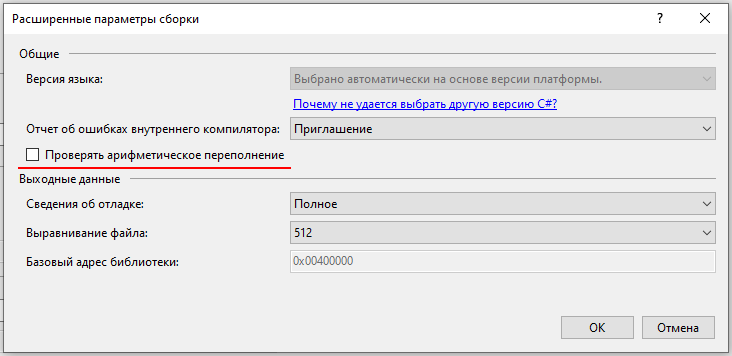
Если создается приложение, в котором переполнение никогда не должно проходить незаметно, может выясниться, что обрамлять ключевым словом checked приходится раздражающе много строк кода. На такой случай в качестве альтернативного варианта в компиляторе C# поддерживается флаг /checked. При активизации этого флага проверки на предмет возможного переполнения будут автоматически подвергаться все имеющиеся в коде арифметические операции, без применения для каждой из них ключевого слова checked. Обнаружение переполнения точно так же приводит к генерации соответствующего исключения во время выполнения.
Для активизации этого флага в Visual Studio необходимо открыть страницу свойств проекта (Проект - свойства), перейти на вкладку Build (Сборка), щелкнуть на кнопке Advanced (Дополнительно) и в открывшемся диалоговом окне отметить флажок Check for arithmetic overflow/underflow (Проверять арифметическое переполнение):
Важно отметить, что в C# предусмотрено ключевое слово unchecked, которое позволяет отключить выдачу связанного с переполнением исключения в отдельных случаях.
Итак, чтобы подвести итог по использованию в C# ключевых слов checked и unchecked, следует отметить, что по умолчанию арифметическое переполнение в исполняющей среде .NET игнорируется. Если необходимо обработать отдельные операторы, то должно использоваться ключевое слово checked, а если нужно перехватывать все связанные с переполнением ошибки в приложении, то понадобится активизировать флаг /checked. Что касается ключевого слова unchecked, то его можно применять при наличии блока кода, в котором переполнение является допустимым (и, следовательно, не должно приводить к генерации исключения во время выполнения).
Роль класса System.Convert
В завершении темы преобразования типов данных стоит отметить, что в пространстве имен System имеется класс Convert, который тоже может применяться для расширения и сужения данных:
byte sum = Convert.ToByte(var1 + var2);
Одно из преимуществ подхода с применением класса System.Convert связано с тем, что он позволяет выполнять преобразования между типами данных нейтральным к языку образом (например, синтаксис приведения типов в Visual Basic полностью отличается от предлагаемого для этой цели в C#). Однако, поскольку в C# есть операция явного преобразования, использование класса Convert для преобразования типов данных обычно является делом вкуса. :)
Оператор присваивания
Оператор присваивания обозначается одиночным знаком равенства (=). В C# оператор присваивания действует таким же образом, как и в других языках программирования. Ниже приведена его общая форма:
имя_переменной = выражение
Здесь имя_переменной должно быть совместимо с типом выражения. У оператора присваивания имеется одна интересная особенность, о которой вам будет полезно знать: он позволяет создавать цепочку операций присваивания. Рассмотрим следующий фрагмент кода:
int x, у, z;
x = у = z = 10; // присвоить значение 10 переменным x, у и z
В приведенном выше фрагменте кода одно и то же значение 10 задается для переменных х, у и z с помощью единственного оператора присваивания. Это значение присваивается сначала переменной z, затем переменной у и, наконец, переменной х. Такой способ присваивания "по цепочке" удобен для задания общего значения целой группе переменных.
Составные операторы присваивания
В C# предусмотрены специальные составные операторы присваивания, упрощающие программирование некоторых операций присваивания. Обратимся сначала к простому примеру:
x = x + 1;
// Можно переписать следующим образом
x += 1;
Пара операторов += указывает компилятору на то, что переменной х должно быть присвоено ее первоначальное значение, увеличенное на 1.
Для многих двоичных операций, т.е. операций, требующих наличия двух операндов, существуют отдельные составные операторы присваивания. Общая форма всех этих операторов имеет следующий вид:
имя переменной op = выражение
где op — арифметический или логический оператор, применяемый вместе с оператором присваивания. Ниже перечислены составные операторы присваивания для арифметических и логических операций:
| Оператор | Аналог (выражение из вышеуказанного примера) |
|---|---|
| += | x = x + 1; |
| -= | x = x - 1; |
*= |
x = x * 1; |
| /= | x = x / 1; |
| %= | x = x % 1; |
| |= | x = x | 1; |
| ^= | x = x ^ 1; |
Составные операторы присваивания записываются более кратко, чем их несоставные эквиваленты. Поэтому их иногда еще называют укороченными операторами присваивания.
У составных операторов присваивания имеются два главных преимущества. Во-первых, они более компактны, чем их "несокращенные" эквиваленты. И во-вторых, они дают более эффективный исполняемый код, поскольку левый операнд этих операторов вычисляется только один раз. Именно по этим причинам составные операторы присваивания чаще всего применяются в программах, профессионально написанных на C#.
Операции с числами
Арифметические операции
Арифметические операторы, представленные в C#, приведены ниже:
| Оператор | Действие |
|---|---|
| + | Сложение |
| - | Вычитание, унарный минус |
| * | Умножение |
| / | Деление |
| % | Деление по модулю |
| -- | Декремент |
| ++ | Инкремент |
Операторы +,-,* и / действуют так, как предполагает их обозначение. Их можно применять к любому встроенному числовому типу данных.
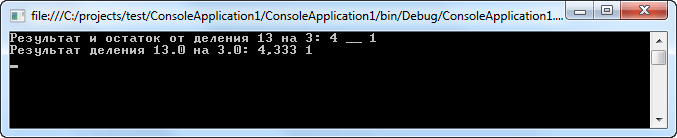
Действие арифметических операторов не требует особых пояснений, за исключением следующих особых случаев. Прежде всего, не следует забывать, что когда оператор / применяется к целому числу, то любой остаток от деления отбрасывается; например, результат целочисленного деления 13/3 будет равен 4. Остаток от этого деления можно получить с помощью оператора деления по модулю (%), который иначе называется оператором вычисления остатка. Он дает остаток от целочисленного деления. Например, 13 % 3 равно 1. В C# оператор % можно применять как к целочисленным типам данных, так и к типам с плавающей точкой. Поэтому 13.0 % 3.0 также равно 1. В этом отношении C# отличается от языков С и С++, где операции деления по модулю разрешаются только для целочисленных типов данных. Давайте рассмотрим следующий пример:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
int num1, num2;
float f1, f2;
num1 = 13 / 3;
num2 = 13 % 3;
f1 = 13.0f / 3.0f;
f2 = 13.0f % 3.0f;
Console.WriteLine("Результат и остаток от деления 13 на 3: {0} __ {1}",num1,num2);
Console.WriteLine("Результат деления 13.0 на 3.0: {0:#.###} {1}", f1, f2);
Console.ReadLine();
}
}
}
Результат работы данной программы:
Операторы инкремента и декремента
Оператор инкремента (++) увеличивает свой операнд на 1, а оператор декремента (--) уменьшает операнд на 1. Следовательно, операторы:
x++;
x--;
равнозначны операторам:
x = x + 1;
x = x - 1;
Следует, однако, иметь в виду, что в инкрементной или декрементной форме значение переменной x вычисляется только один, а не два раза. В некоторых случаях это позволяет повысить эффективность выполнения программы.
Обa оператора инкремента и декремента можно указывать до операнда (в префиксной форме) или же после операнда (в постфиксной форме). Давайте разберем разницу записи операции инкремента или декремента на примере:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
short d = 1;
for (byte i = 0; i < 10; i++)
Console.Write(i + d++ + "\t");
Console.WriteLine();
d = 1;
for (byte i = 0; i < 10; i++)
Console.Write(i + ++d + "\t");
Console.ReadLine();
}
}
}
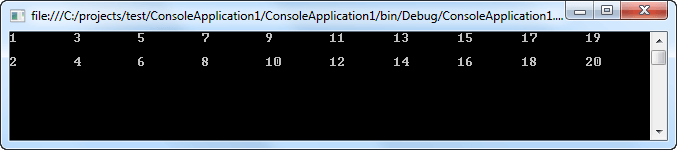
Т.е. операция инкремента в префиксной форме происходит раньше, нежели в постфиксной форме, в результате чего числа из второго ряда получаются на единицу больше. Отмечу, что возможность управлять моментом инкремента или декремента дает немало преимуществ при программировании.
Поразрядные операторы
В C# предусмотрен ряд поразрядных операторов, расширяющих круг задач, для решения которых можно применять C#. Поразрядные операторы воздействуют на отдельные двоичные разряды (биты) своих операндов. Они определены только для целочисленных операндов, поэтому их нельзя применять к данным типа bool, float или double.
Эти операторы называются поразрядными, поскольку они служат для проверки, установки или сдвига двоичных разрядов, составляющих целое значение. Среди прочего поразрядные операторы применяются для решения самых разных задач программирования на уровне системы, включая, например, анализ информации состояния устройства. Все доступные в C# поразрядные операторы приведены ниже:
| Оператор | Значение |
|---|---|
| & | Поразрядное И |
| | | Поразрядное ИЛИ |
| ^ | Порязрядное исключающее ИЛИ |
<< |
Сдвиг влево |
>> |
Сдвиг вправо |
| ~ | Дополнение до 1 (унарный оператор НЕ) |
Поразрядные операторы И, ИЛИ, исключающее ИЛИ и НЕ
Поразрядные операторы И, ИЛИ, исключающее ИЛИ и НЕ обозначаются следующим образом: &, |, ^ и ~. Они выполняют те же функции, что и их логические аналоги. Но в отличие от логических операторов, поразрядные операторы действуют на уровне отдельных двоичных разрядов.
С точки зрения наиболее распространенного применения поразрядную операцию И можно рассматривать как способ подавления отдельных двоичных разрядов. Это означает, что если какой-нибудь бит в любом из операндов равен 0, то соответствующий бит результата будет сброшен в 0. Поразрядный оператор ИЛИ может быть использован для установки отдельных двоичных разрядов. Если в 1 установлен какой-нибудь бит в любом из операндов этого оператора, то в 1 будет установлен и соответствующий бит в другом операнде. Поразрядный оператор исключающее ИЛИ устанавливает двоичный разряд операнда в том и только в том случае, если двоичные разряды сравниваемых операндов оказываются разными, как в приведенном ниже примере. Для понимания вышесказaнного, разберите следующий пример:

Давайте теперь рассмотрим пример программы, использующей поразрядные операторы:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
chet(16);
provChet(8);
nechet(16);
Console.ReadLine();
}
// Метод, преобразующий все нечетные числа в четные
// в диапазоне [0, x] c помощью
// поразрядного оператора &
static void chet(int x)
{
int result;
Console.WriteLine("Преобразованный диапазон чисел от 0 до {0}:\n",x);
for (int i = 0; i <= x; i++)
{
// Сбрасываем младший разряд числа, чтобы
// получить четное число
result = i & 0xFFFE;
Console.Write("{0}\t",result);
}
}
// Метод, проверяющий является ли число четным
static void provChet(int x)
{
Console.WriteLine("\n\nПроверка четности чисел в диапазоне от 1 до {0}\n",x);
for (int i = 1; i <= x; i++)
{
if ((i & 1) == 0)
Console.WriteLine("Число {0} - является четным",i);
else
Console.WriteLine("Число {0} - является нечетным",i);
}
}
// Метод, преобразующий четные числа в нечетные
// с помощью поразрядного оператора |
static void nechet(int x)
{
int result;
Console.WriteLine("\nПреобразованный диапазон чисел от 0 до {0}:\n",x);
for (int i = 0; i <= x; i++)
{
result = i | 1;
Console.Write("{0}\t",result);
}
}
}
}
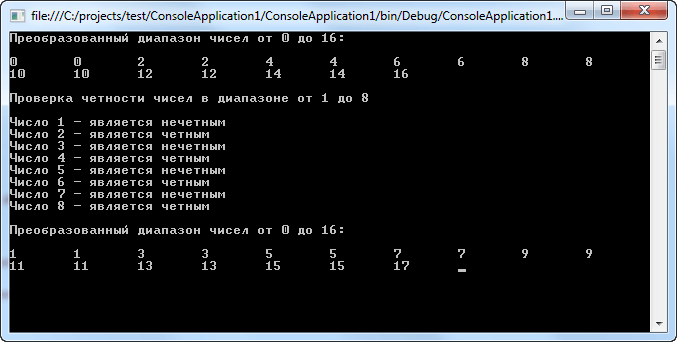
Операторы сдвига
В C# имеется возможность сдвигать двоичные разряды, составляющие целое значение, влево или вправо на заданную величину. Ниже приведена общая форма для этих операторов:
значение << число_битов
значение >> число битов
где число_битов — это число двоичных разрядов, на которое сдвигается указанное значение.
При сдвиге влево все двоичные разряды в указываемом значении сдвигаются на одну позицию влево, а младший разряд сбрасывается в нуль. При сдвиге вправо все двоичные разряды в указываемом значении сдвигаются на одну позицию вправо. Если вправо сдвигается целое значение без знака, то старший разряд сбрасывается в нуль. А если вправо сдвигается целое значение со знаком, то разряд знака сохраняется. Напомним, что для представления отрицательных чисел старший разряд целого числа устанавливается в 1. Так, если сдвигаемое значение является отрицательным, то при каждом сдвиге вправо старший разряд числа устанавливается в 1. А если сдвигаемое значение является положительным, то при каждом сдвиге вправо старший разряд числа сбрасывается в нуль.
При сдвиге влево и вправо крайние двоичные разряды теряются. Восстановить потерянные при сдвиге двоичные разряды нельзя, поскольку сдвиг в данном случае не является циклическим. Рассмотрим пример:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
byte n = 6, result;
// Умножить на 2
result = (byte)(n << 1);
Console.WriteLine("{0} * 2 = {1}",n,result);
// Умножить на 4
result = (byte)(n << 2);
Console.WriteLine("{0} * 4 = {1}",n,result);
// Разделить на 2
result = (byte)(n >> 1);
Console.WriteLine("{0} / 2 = {1}",n,result);
Console.ReadLine();
}
}
}
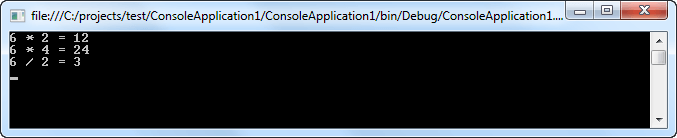
КОНТРОЛЬНЫЕ ВОПРОСЫ:
- что такое пространство имен и для чего оно нужно?
- Какими символами обозначаются комментарии?
- Чем характеризуетя переменная?
- Какие типы данных по-умолчанию используются для целых чисел и для чисел с плавыющей запятой?
- За что отвечают ключевые слова checked и unchecked?
| Предыдущая лекция | Следующая лекция | |
|---|---|---|
| Системы контроля версий. | Содержание | [Операторы и операции языка. (./articles/t3l1_2.md) |